Reproducing a String Theory Vacuum in Rust

Why does this universe exist? Why is there anything at all?
One night, I got tired of wondering about these questions, so I decided to roll up my sleeves and see if I might be able to help to figure out some answers. Because why not? So for the last six months, one of my new hobbies has been string theory research. I've spent many nights reproducing a frontier result in string theory, porting a Python physics library to Rust, and standing up a genetic algorithm on my home server that searches the "landscape" of string vacua for one that might explain dark energy.
First: I am not a physicist, and I still don't really understand anything about string theory. I've had to learn everything from scratch, and almost all of the heavy lifting was done by AI coding agents. (AI is very, very good at physics and mathematics now.) Second: this work has not found a theory of everything, and it has not yet found a single verified dark-energy vacuum. What it has done is reproduce a published string-theory calculation exactly, from first principles, and turn that into a fast, type-safe engine that now runs a real search 24/7.
The physics, in five minutes
String theory only makes sense in ten dimensions. To connect it to our four-dimensional world, you roll up the extra six dimensions into a tiny, intricate shape called a Calabi-Yau manifold. There are enormous numbers of these shapes, and on each one you can thread different amounts of "flux" (think of it as generalized magnetic field lines) through the manifold's holes. Each choice of shape + flux gives a different effective four-dimensional universe, with different physics. The set of all of them is the string landscape, and it is famously, absurdly large — the figure that gets thrown around is something like 10^272,000 distinct flux vacua.
Two numbers about our universe are spectacularly hard to explain:
- The cosmological constant. Empty space has an energy density, and ours is tiny and positive — about 10^-122 in natural (Planck) units. Naive estimates from quantum field theory are off by ~120 orders of magnitude. This is widely considered the worst prediction in physics.
- Dark energy's behavior. Until recently, we assumed that vacuum energy was a true constant (Λ). But the DESI survey has been publishing data hinting that dark energy might be slowly weakening over time — that it's not a constant at all, but a scalar field still gently rolling downhill. In string theory that rolling field is the most natural thing in the world: it's a modulus, one of the geometric parameters of the Calabi-Yau. A rolling-scalar dark energy is called quintessence.
Here's the punchline that makes this exciting rather than embarrassing for string theory: building a stable, eternal, positive cosmological constant in string theory has been notoriously, painfully difficult for two decades (the "de Sitter problem"). But a slowly decaying dark energy — quintessence — is exactly what a lot of string theorists have been predicting since 2018, on "swampland" grounds. If DESI's trend holds, it's arguably the first observational hint in favor of the string-theoretic expectation.
So the dream is: find a specific Calabi-Yau + flux that produces a vacuum energy of the right tiny size and whose rolling-modulus dark energy matches the equation of state DESI measures. That would be a concrete, UV-complete, falsifiable string-theory model of the dark energy we actually observe.
To even attempt that search, you need to be able to compute the vacuum energy of a candidate exactly. Which brings us to McAllister.
The calibration target: an explicit vacuum with a tiny cosmological constant
In 2021, McAllister, Demirtas, Kim and collaborators published one of the only fully explicit, end-to-end constructions of a string vacuum with an exponentially small, controlled cosmological constant. They did it on one specific Calabi-Yau — a reflexive polytope from the Kreuzer-Skarke database with Hodge numbers (h¹¹, h²¹) = (214, 4), which everyone in this corner of the field just calls "4-214-647."
The numbers they get are wild:
| Quantity | Value | ||
|---|---|---|---|
| string coupling g_s | ≈ 0.00911 | ||
| flux superpotential \ | W₀\ | ≈ 2.3 × 10⁻⁹⁰ | |
| Calabi-Yau volume | ≈ 4711.83 | ||
| vacuum energy V₀ | ≈ −5.5 × 10⁻²⁰³ |
That last number — a cosmological constant 203 orders of magnitude below the natural scale — is the headline. It comes from a delicate cancellation: the flux superpotential W₀ is already tiny (~10⁻⁹⁰), and then non-perturbative effects nearly cancel it, leaving |W| even smaller. Square that and you're at 10⁻²⁰³.
Reproducing this is the obvious first move. If I can't reproduce a published number exactly, I have no business searching for new ones — I'd never know whether a "hit" was real physics or a bug.
I figured it would take a couple of weeks. It took many months.
The long struggle: "discrepancies are gold"
The thing about a number like 10⁻²⁰³ is that you cannot eyeball whether it's right. The whole pipeline — polytope → triangulation → intersection numbers → flat direction → racetrack → superpotential → volume → vacuum energy — is a long chain where each stage feeds the next, and a single wrong sign or off-by-one index anywhere produces a different, equally plausible-looking, completely wrong answer. You only find out you're wrong by failing to match the paper, and even then you have no idea which of a dozen stages is lying to you.
So I adopted a rule, which became the emotional core of the whole project: a discrepancy is not a problem, it's the entire point. Every time our number disagreed with McAllister's, that disagreement was a bug with a specific physical cause, and the job was to understand it completely — no shortcuts, no "close enough," no silently substituting the paper's value to make a test pass. Here's one of the guardrails I wrote for the project:
"This is not building a SaaS. This is high energy theory physics. This is formal verification. This is launching rockets. A single sign error, a single wrong index, a single misunderstood coordinate system will produce garbage that looks plausible. Either the physics is exactly right or it's meaningless."
Here are a few of the bugs.
The two different 4×'s. Early on the volume came out as 17,901 instead of 4,711 — a factor of about 3.8, suspiciously close to 4. The cause was that CYTools (the standard Python toolkit for this) had silently changed its default choice of "divisor basis" between the 2021 version McAllister used and the current one. McAllister's stored flux vectors were written in the old basis; feeding them through the new basis corrupted everything downstream. And there was a subtle sub-bug inside the fix: the two flux vectors K and M transform differently under a basis change (one covariant, one contravariant), and the original code transformed both the same way. To make it worse, there was a second, unrelated ~3.8× error lurking — using the uncorrected Kähler moduli instead of the instanton-corrected ones also gives ~3.8× the right volume. Two different near-4× bugs that had to be told apart.
The 16/9 that was a misplaced parenthesis. One factor, e^{K₀}, kept coming out 16/9 ≈ 1.78× too large. The cause was reading equation (6.12) wrong: the paper writes e^{K₀} = (4/3 · κ p³)⁻¹, where the inverse applies to the whole product — i.e. (3/4)/(κp³), not (4/3)/(κp³). The ratio between the wrong and right readings is exactly (4/3)/(3/4) = 16/9. A LaTeX parenthesis cost days.
The hero bug: a B-field on the wrong divisors. This was the last thing standing between "close" and "exact". After fixing everything else, the volume was still off — by a stubborn, tiny +0.0718 that would not go away. Codex went down a deep rabbit hole convinced the cause was nine "missing" curve invariants that seemed to require some exotic orbifold Gromov-Witten machinery (Chen-Ruan cohomology, twisted I-functions). It was a dead end. The real cause was almost insultingly small: the function building the orientifold's B-field parity vector was constructing it from the wrong set of divisors, giving 49 odd entries when the true answer has 51. The two missing entries corresponded to two specific lattice points (points 2 and 46) that sit outside the basis I was iterating over. With the wrong parity, two of ten curves got the wrong sign in an analytic continuation, and the vacuum settled into the wrong adjacent geometric "chamber" — off by exactly that 0.0718. Fix the parity vector, and the volume snaps to 4711.4264 and log₁₀|V₀| lands on −202.2628.
A sign error on 2 of 10 curves, from an under-counted parity vector, hiding behind a 200-digit number. This bug was finally cracked by Claude Fable 5. I wouldn't have been able to finish the paper reproduction and move on to the GA without Fable 5.
There's also a small α′ correction to the volume — −ζ(3)·χ/(4(2π)³) ≈ 0.509 — that's tempting to ignore because it's tiny. It is not optional. Leave it out and V is wrong by half, which propagates straight into V₀. (The project notes have this one in all-caps.)
After all of it: the pipeline now reproduces log₁₀|V₀| = −202.26 from first principles — starting from nothing but the polytope's lattice points and the flux integers, computing every intermediate quantity live, never loading a precomputed value. (The test suite is deliberately built so cheating is impossible: what we compute and what McAllister published live in separate directories, and a stage that loaded the answer instead of computing it would just fail.) Not just for 4-214-647, but for all five vacua in the paper. And when I later ran a sanity sweep — 94 random Calabi-Yaus, comparing our Rust output against CYTools on identical inputs — it was 94/94 exact matches, zero divergence.
That green checkmark was finally the license to do everything that comes after.
Why Rust?
The original prototype was Python — a "Frankenstein" of a Rust genetic-algorithm driver calling out through PyO3 to Python, which imported CYTools, JAX, and some C++ tools. It worked. It proved the physics. But it was far too slow to search with, and the dynamically-typed numerics made the sign-and-NaN bugs above easy to write and hard to catch.
So I decided to reimplement the whole thing in Rust. The library I was porting, CYTools, does the core Calabi-Yau computations: lattice polytopes, triangulations, intersection numbers, cone computations, curve-counting invariants. The porting philosophy I adopted (and wrote into the project rules):
"Rust bindings don't matter. You can reimplement entire libraries in minutes. Don't waste time searching for Rust crates with bindings. Find the algorithm in ANY language — C++, Python, Fortran, whatever — understand it, and port it. Don't search for Rust bindings. Just port the algorithm."
So the Double Description Method for dualizing cones came from reading the PPL and cddlib C/C++ source; LLL lattice reduction came from the FLINT-based version CYTools uses; the triangulation circuits came from the CYTools source itself. (I won't pretend it's 100% pure: linear programming uses the good_lp + HiGHS crate rather than a hand-port, and — honestly — the hardest piece, the Gopakumar-Vafa series inversion, reuses the excellent cygv crate. I port the scaffolding around it, not the HKTY engine itself.)
The part I'm genuinely proud of is the type system for the numbers. Every quantity in the codebase is a phantom-typed wrapper — F64<Pos>, F64<NonNeg>, F64<NonZero>, F64<Finite> — and these tags carry a compile-time algebra:
let a: F64<Pos> = pos!(3.0);
let b: F64<Neg> = neg!(-2.0);
let c: F64<Neg> = a * b; // Pos * Neg = Neg — the compiler tracks the sign
let d: F64<Pos> = a * a; // Pos * Pos = Pos
Pos * Neg is Neg, Pos * Pos is Pos, Pos + Neg widens to Finite (sign unknown), all enforced at compile time. The tags are zero-sized and the wrapper is #[repr(transparent)], so there is no runtime cost whatsoever — an F64<Pos> is laid out identically to a bare f64.
The single cleanest consequence is a comment in the division module:
"Division by Zero is intentionally not implemented — it won't compile!"
There is simply no Div implementation that accepts a denominator which might be zero. If you have a number that's only known to be Finite, you cannot write a / b until you prove the denominator is nonzero by narrowing its type (try_to_non_zero(), which returns an Option). An entire class of 1/0 → ∞ → NaN-propagates-through-your-vacuum-energy bugs is removed at the language level rather than guarded at runtime. Given that the whole struggle above was about sign errors and silent garbage, encoding "invalid states are unrepresentable" directly into the types felt very important.
On top of that sits a ≥98% test-coverage gate, which I think about less as a quality metric and more as a reading-discipline mechanism — it guarantees every line has been executed (and therefore read) at least twice — and the dual test suite that runs identical inputs through both CYTools and the Rust port and demands bit-identical results.
The scale, for the curious: about 80,000 lines of Rust across two crates (cyrus-core for the math/physics, cyrus-ga for the search). A lot of work — 959 commits across 6 days in early May — came out of one intense sprint where I left a Codex /goal running for 4 days and accidentally spent thousands of dollars on OpenAI tokens. And I still didn't have much to show for it by the end. But then I had access to Claude Fable 5 for a few days in June, and it was finally able to get the project over the finish line.
The search: a genetic algorithm hunting for dark energy
With a trustworthy engine, the actual goal comes into reach: search the landscape for a vacuum whose dark energy matches DESI.
The search is a genetic algorithm. A "genome" is just a pair of integer flux vectors (K, M). The fitness function runs that flux through moduli stabilization to get g_s, |W₀|, and a vacuum energy V₀, and then scores it on how well it matches the dark energy we observe:
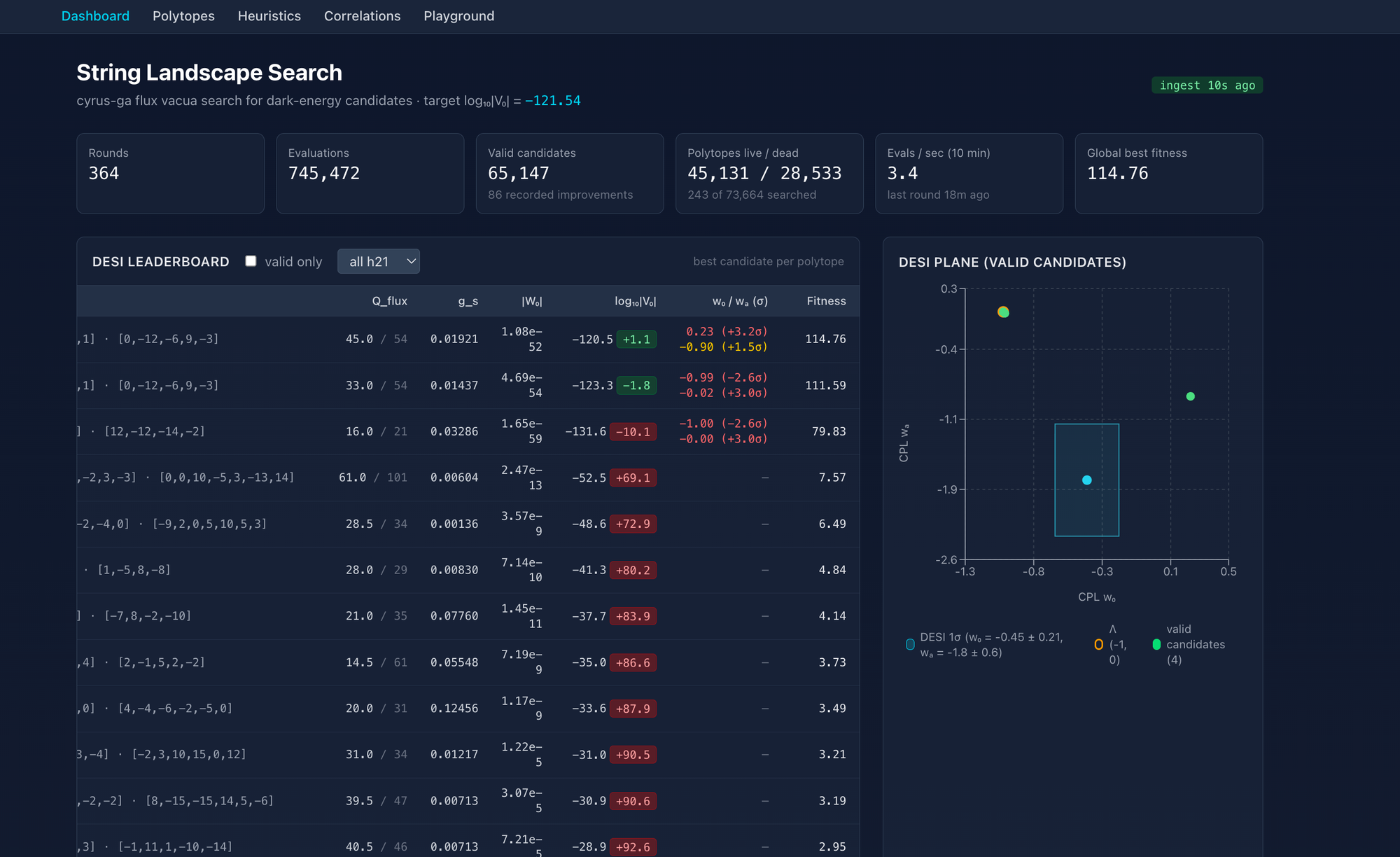
- Height — how close log₁₀|V₀| is to the observed dark-energy scale (≈ −121.5). This term gates everything else.
- Slope — the candidate's energy is dressed up as a rolling-axion quintessence field, evolved through the actual Friedmann + Klein-Gordon cosmology equations, fit to an equation of state w(z), and scored against DESI's measurement (w₀ = −0.45 ± 0.21, wₐ = −1.8 ± 0.6).
- Weak coupling — a small tiebreaker rewarding perturbative control.
There's a "fitness ladder" with strictly ordered bands — invalid candidates are scored by how far through the physics pipeline they got before failing, so the GA gets a smooth gradient to climb even in the vast regions where nothing is valid.
It searches a pool of 73,664 Calabi-Yau polytopes (the full Kreuzer-Skarke set with a small number of complex-structure moduli), with a bandit algorithm deciding how to split effort between exploring fresh geometries and exploiting promising ones.
The most important thing I learned building it: blind random search finds absolutely nothing. Zero valid vacua in 557,000 tries. And that's not bad luck — it's provable. A valid vacuum requires the flux K to be "isotropic" for a certain quadratic form derived from M, which is a measure-zero condition; random integer vectors essentially never satisfy it, and you can't greedily nudge your way onto it. The fix is to constructively solve for isotropic flux seeds, in exact integer arithmetic, at the start of each geometry, and seed the population with those. (Geometries where no seed exists in budget get marked "PFV-barren" and skipped — which means the search is also quietly producing a census of which Calabi-Yaus can't host this kind of vacuum at all.)
Two tiers: a cheap proxy and an expensive truth
Running the full first-principles vacuum-energy computation on every candidate would be hopeless — it takes tens of minutes. So evaluation is two-tiered. A cheap "mirror-side" proxy runs on every genome in microseconds and is good enough for ranking. Only when a candidate looks genuinely promising does the expensive "deep-verify" fire: the full McAllister-style stabilization on the real Calabi-Yau, the same pipeline that reproduces −202.26.
And deep-verify is itself a search, which surprised me. The paper's criterion for choosing the right divisor basis admits thousands of valid options, and they are not interchangeable — most of them land the calculation in a geometric chamber where the curve-counting becomes intractable. Only special chambers stay computable. So deep-verify walks the admissible bases until it finds one whose chamber is fully covered by the cheap curve-counting methods. (As a validation: pointed at McAllister's geometry, this scan independently re-derives his exact basis choice — candidate 437 out of 4,683 — and reproduces −202.26 with no input data file at all.)
Most of my recent work has been making deep-verify fast and safe enough to run inside a live search:
- A precompute that hoists the geometry-fixed part of the curve-counting out of the per-candidate loop cut the cost about 9×.
- A key realization: whether a chamber is computable depends only on the geometry, not on the flux. So the expensive scan can be cached per polytope — paid once, ever, instead of re-run for every candidate. Without this, enabling deep-verify would have re-scanned thousands of bases on every generation and ground the search to a halt.
- And the trigger is physical: deep-verify only fires on candidates whose proxy dark-energy equation of state already sits within 1σ of DESI. No point running a tens-of-minutes verification on a vacuum that, even if real, wouldn't look like our universe.
Running it on my server
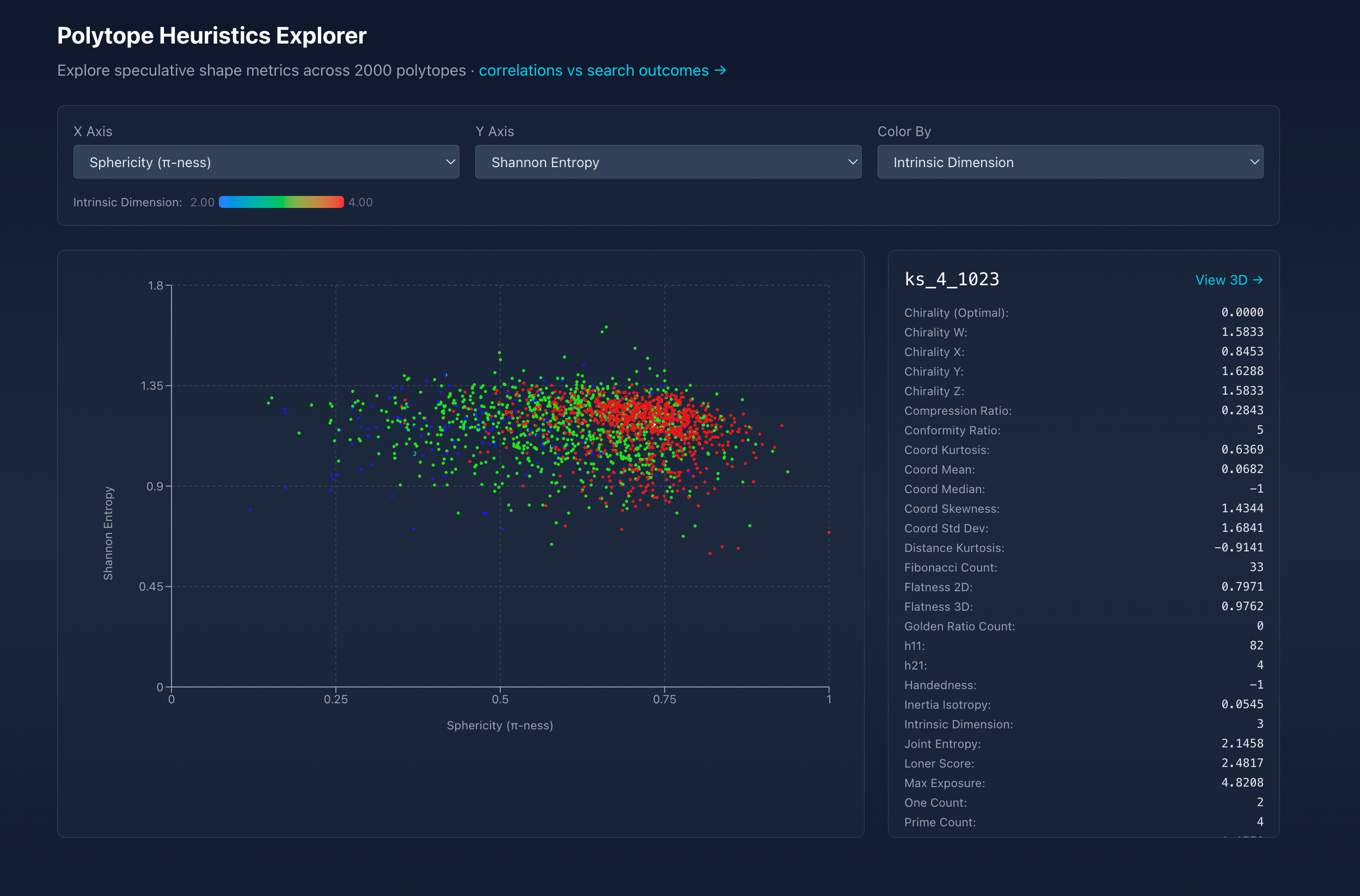
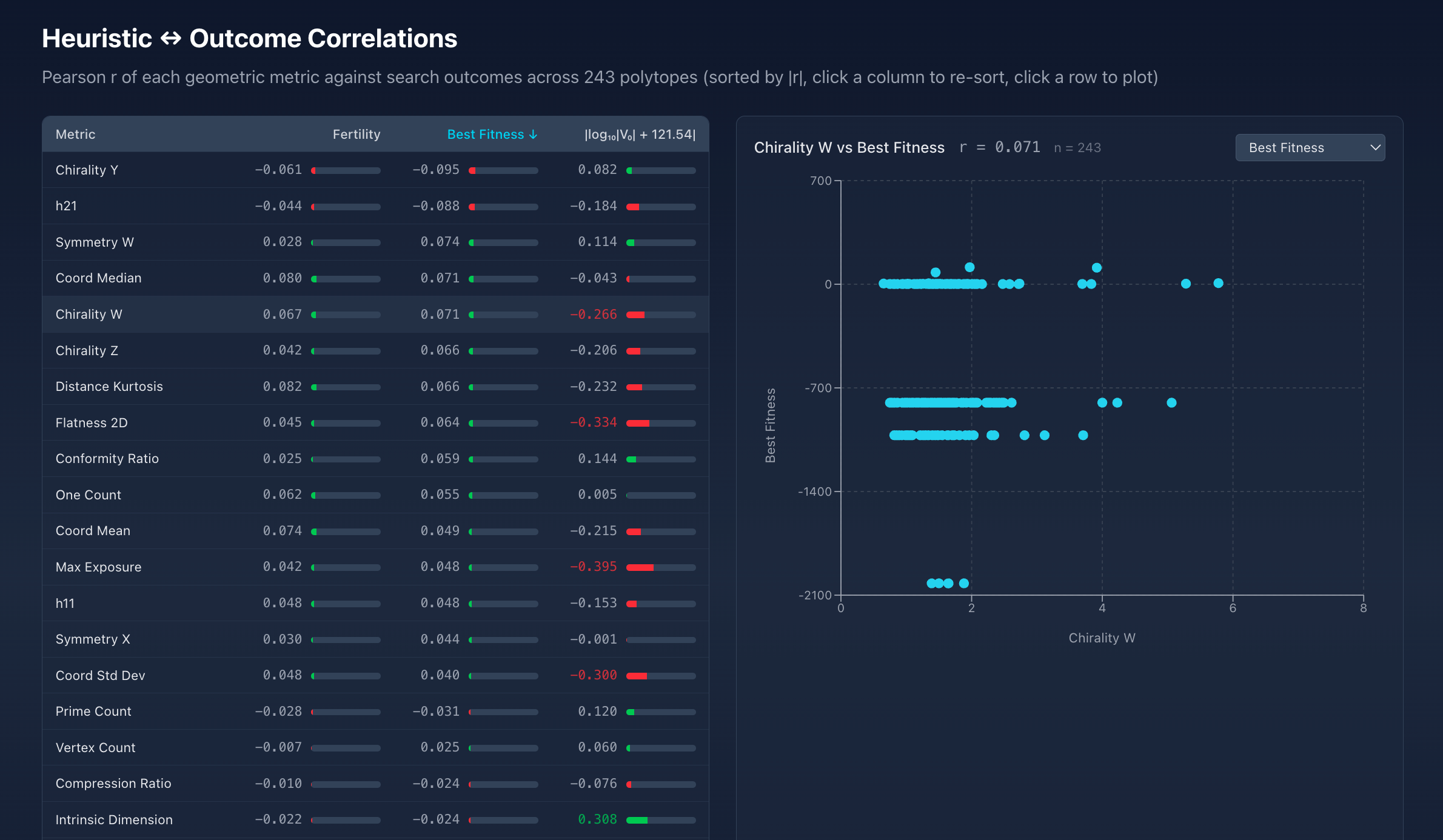
All of this runs 24/7 on a server in my house, deployed with Ansible. It's a small fleet of systemd services: the genetic algorithm itself (16 threads, fully checkpointed so it survives restarts and resumes exactly where it left off), a daemon that tails the GA's output into a SQLite database, a web dashboard, and a job that computes ~40 geometric "shape" metrics over all 73,664 polytopes to see if I can find any correlations (just as an experiment).
The dashboard is a live DESI leaderboard, and a scatter plot of every valid candidate's predicted (w₀, wₐ) against the DESI 1σ box, with the cosmological-constant point (−1, 0) marked for reference.
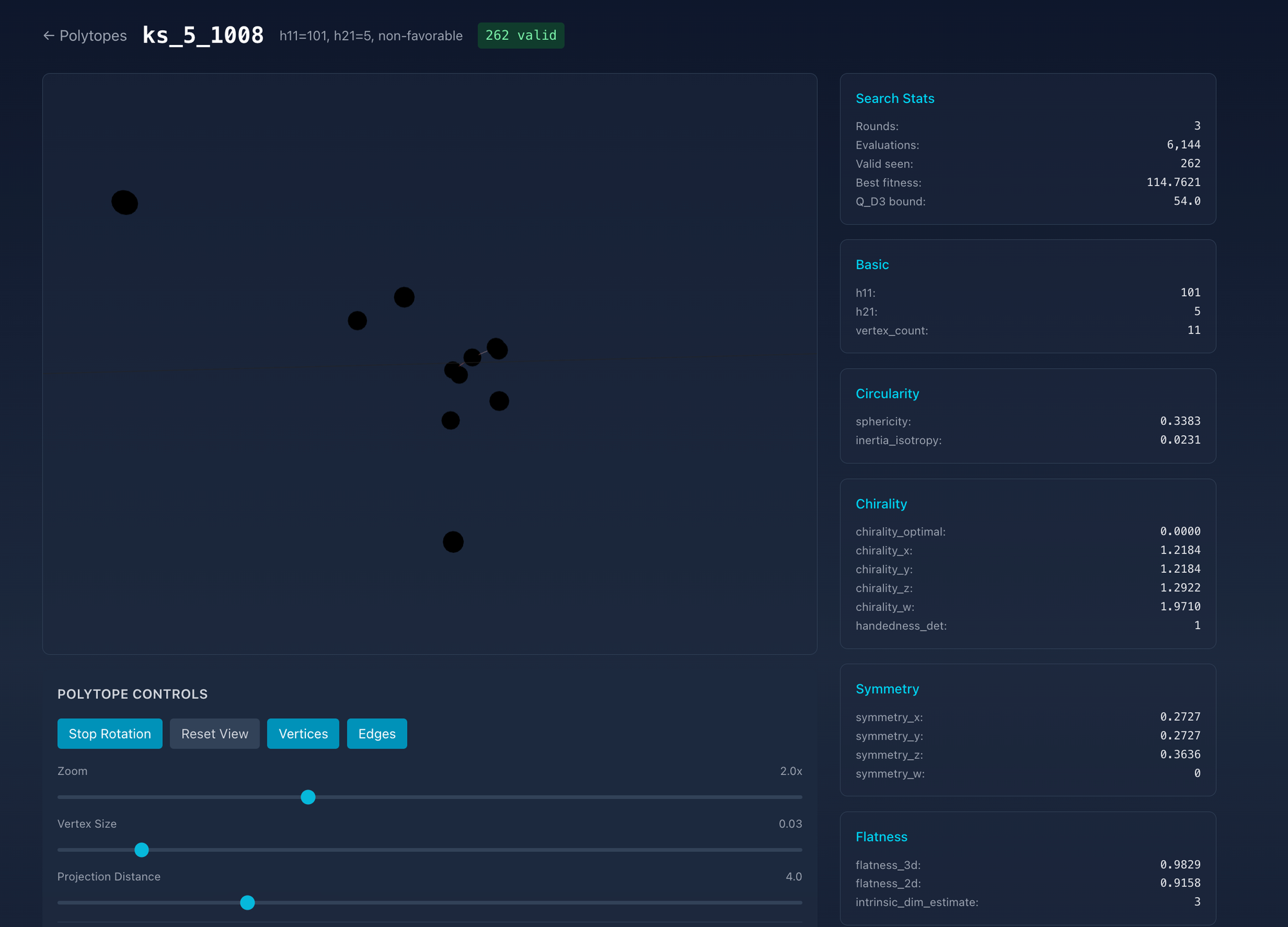
There is a page to inspect the shape of each polytope:
What it's actually found
Nothing yet. It has not found a verified dark-energy vacuum. The search surfaces near-misses — candidates whose vacuum energy lands within a fraction of a log of the observed dark-energy scale, and whose equation of state comes within ~1–3σ of DESI. But every single leaderboard leader so far has died under the full deep-verify: either no computable chamber exists, or the real solution sits too many "flops" away across geometric walls, or a refinement reveals the promising-looking number was a truncation artifact.
That's to be expected. The most important property I built into it is that it's honest by construction: a candidate only climbs into the top tier by surviving the same first-principles calculation that reproduces the published McAllister number. Every dead leader added a permanent new gate.
And even if it does one day find a verified, DESI-matching, fully-controlled vacuum, I want to be clear about what that would and wouldn't mean. It would be a genuine, significant thing: a controlled, UV-complete string-theory realization of the observed dark energy, with the moduli actually stabilized and the approximations under control. It would not be a theory of everything. The dark-energy sector and the Standard Model live in different parts of the construction — the bulk geometry versus the branes wrapping it — and matching a handful of cosmological numbers says essentially nothing about whether the same Calabi-Yau also contains three generations of quarks and leptons. That's a separate, even harder search. Matching DESI would be a real result about dark energy, full stop.
A note on method: directing AI agents to do physics
Again, I am not a string theorist. The vast majority of the 80,000 lines of Rust, and a lot of the physics debugging, was done by AI coding agents — Claude, Codex, and others — working under an unusually strict regime that I spent a lot of time designing.
The interesting finding is that the strictness is what made it work. Frontier physics is the worst possible domain for the way LLMs like to behave: they love to paper over a discrepancy, fall back to a plausible default, or quietly load the expected answer to make a test go green. Every one of those instincts is fatal here, because the failure mode of this domain is plausible garbage. So the project rules are essentially a long list of forbidden shortcuts — "no silent fallbacks," "discrepancies are gold, stop and understand them," "never load a precomputed value where production computes it," "if it isn't implemented, the test should fail, not cheat" — backed by mechanical enforcement: the type system that won't let you divide by zero, the coverage gate that forces every line to be read, the dual test suite that catches any divergence from CYTools. The human job became less "write the code" and more "design the constraints so that the only way to make progress is to get the physics actually right" — and then chase down the discrepancies the constraints surfaced.
What's next
The engine is done and trustworthy, and the search is running. The honest status is: a correctly-built machine, reporting honestly that it hasn't found anything yet.
A verified candidate wouldn't be a philosophical claim — it would predict a specific dark energy equation of state w(z), and DESI's next data releases and the Euclid mission will measure exactly that curve over the next few years. The landscape is unimaginably large, the odds on any given run are long, and I might never find one. But the tooling now exists to look, it's open and reproducible, and every result it reports has survived a calculation that exactly reproduces the published state of the art.
Here is the source code for Cyrus:
And here are the other repos I used to organize my research and to help with project planning: